SREとは?分かりやすく解説!インフラ運用を成功に導く8つの原則と事例
タジケン
テクラル合同会社

SRE(Site Reliability Engineering)とは、システムの信頼性向上と開発スピードの両立を目指し、インフラ運用にソフトウェアエンジニアリングの手法を適用するアプローチです。手作業による運用保守をコードと自動化に置き換えることで、ビジネスの成長を支える安定した基盤を構築します。本記事では、SREとは何かをわかりやすく紐解き、組織への導入と運用を成功させる8つの原則や具体的な事例を解説します。
SREとは?インフラ運用をソフトウェアで解決する
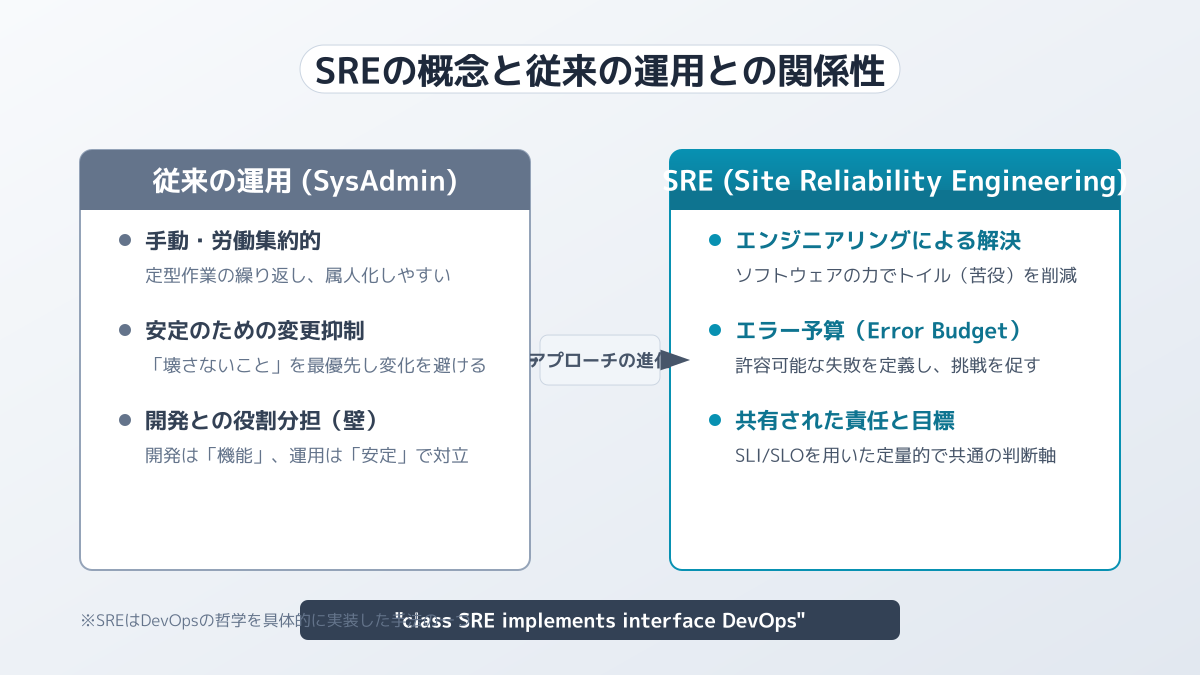
SREとは、Googleが提唱したシステム管理とサービス運用の実践的な手法です。従来のシステム管理では、インフラの構築や障害対応を運用担当者が手作業で行うことが一般的でした。しかし、SREではプログラミングや自動化ツールを用いて、これらの運用課題をソフトウェアの力で解決します。
具体的なインフラ構成の事例として、従来はサーバーの増減を手動で行っていた運用を、AWSのAuto ScalingやTerraformといったInfrastructure as Code(IaC)ツールを用いて自動化するケースが挙げられます。これにより、トラフィックの急増時にもヒューマンエラーを防ぎながらスケーラブルな運用体制を維持できます。
システムの規模が拡大するにつれて、手作業による運用では工数が限界を迎え、新機能の開発スピードを落とす原因になります。SREを導入することで、インフラ基盤がコードとして管理され、安定した運用体制を構築できます。
DevOpsや従来のインフラ運用との違い
SREを深く理解するためには、従来のインフラ運用やDevOpsとの違いを整理することが重要です。
| 項目 | 従来のインフラ運用 | DevOps | SRE |
|---|---|---|---|
| 主な目的 | システムの安定稼働と保守 | 開発と運用のサイロ化解消 | 信頼性と開発速度の両立 |
| アプローチ | 手作業による運用手順の実行 | 文化の醸成とプロセスの改善 | ソフトウェアエンジニアリングによる自動化 |
| 評価指標 | 稼働率(100%を目指す) | デプロイ頻度、リードタイム | SLI、SLA、エラーバジェット |
DevOpsは「開発(Development)と運用(Operations)が協力し、価値を素早くユーザーに届ける」という文化や概念です。一方、SREはそのDevOpsの理想を実現するための具体的な実践方法と位置づけられます。特に新規事業では、初期段階からこの考え方を取り入れることが強固な基盤作りに繋がります。SaaS開発とは?費用相場から技術選定、MVP構築の手順まで完全ガイド も参考に、開発体制を検討してみてください。
エラーバジェットによる開発速度の維持

SREの最大の特徴は、システムの稼働率100%を目指さない点にあります。完璧な稼働を求めすぎると、新機能のリリースやシステム改修ができなくなり、結果的にビジネスの成長を阻害してしまうからです。
ここで重要になるのが「エラーバジェット(許容できる障害の予算)」という概念です。例えば「月の稼働率99.9%を目標にする」と決めた場合、残りの0.1%(約43分間)のダウンタイムがエラーバジェットとなります。
具体的な運用トラブルの解決例として、新機能のリリース直後にAPIのレスポンス遅延が頻発し、エラーバジェットを使い切ってしまったケースを考えてみましょう。エラーバジェットの残量がゼロになった時点で、開発チームは新機能のデプロイを一時停止し、システムの安定性向上(バグ修正やデータベースのクエリ最適化、テスト強化)にリソースを全振りします。これにより、ユーザーの信頼を損なう致命的なダウンタイムを未然に防ぎ、客観的な数値ルールに基づいた運用が可能になります。
トイル(手作業)の継続的な削減
インフラ運用における反復的で自動化可能な手作業のことを、SREでは「トイル(Toil)」と呼びます。例えば、深夜に発生するサーバーの再起動や、ディスク容量不足の定型的なアラート対応は典型的なトイルです。
SREではこれを放置せず、AWS Lambdaなどのサーバーレス環境を用いて自動復旧の仕組みを構築します。具体的な運用トラブルの解決例として、WebサーバーのCPU使用率やメモリが閾値を超えた際、監視ツールのアラートをトリガーにして自動復旧スクリプトを実行し、自動でサーバーの再起動やスケールアウトを行う構成が挙げられます。
このようにエンジニアの業務時間のうちトイルの割合を50%以下に抑え、残りの時間をシステムの改善や自動化の開発にあてることを推奨しています。運用業務の自動化を進めることで、運用負荷を一定に保ちながらビジネスをスケールさせることができます。自動化に向けた各種スクリプト作成の効率化には、プロンプトエンジニアリングとは?生成AIの精度を劇的に高める5つの実践アプローチ などのツール活用も有効です。
SREエンジニアの役割とスキル
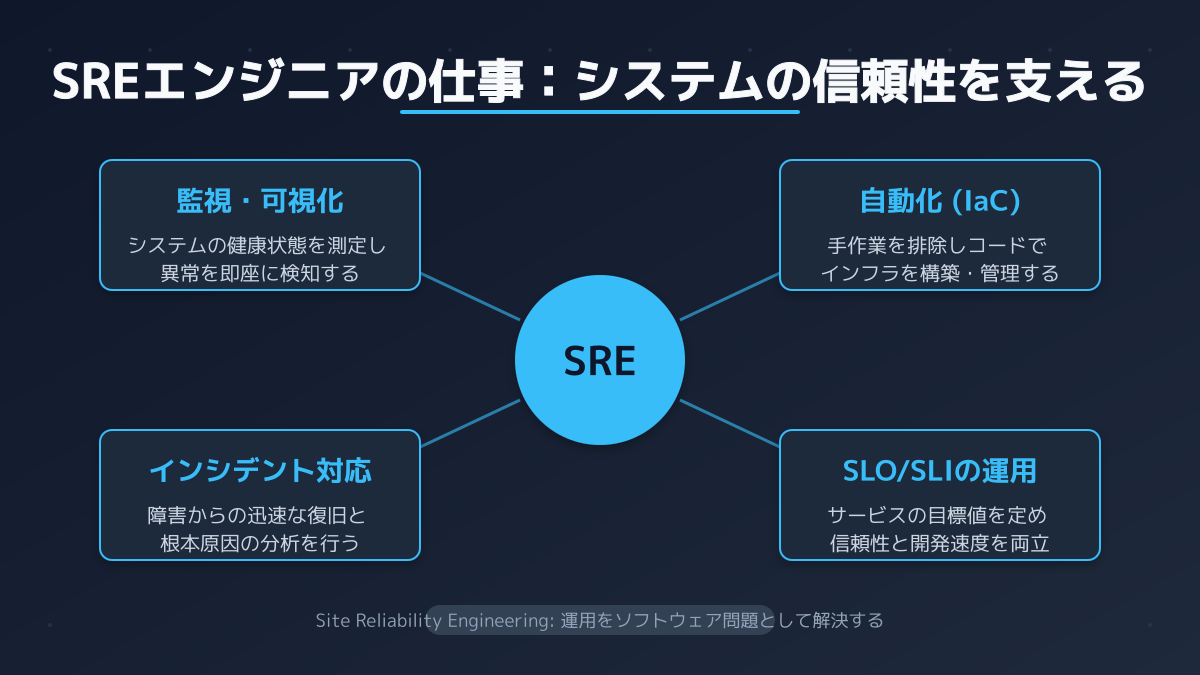
従来のインフラエンジニアがサーバーやネットワークの保守を主務としていたのに対し、SREエンジニアはソフトウェア開発のスキルを武器に運用の効率化を推進します。
求められるスキルセットは広範で、OSやネットワークの深い知識に加え、クラウドインフラ(AWS、GCPなど)のアーキテクチャ設計、Infrastructure as Code(IaC)を用いた環境構築、そして自動化ツールを作成するためのプログラミング能力(Python、Goなど)が必要です。開発チームと同等の技術力を持ち、システムの信頼性を設計段階から担保する役割を担います。
段階的なSRE導入の進め方
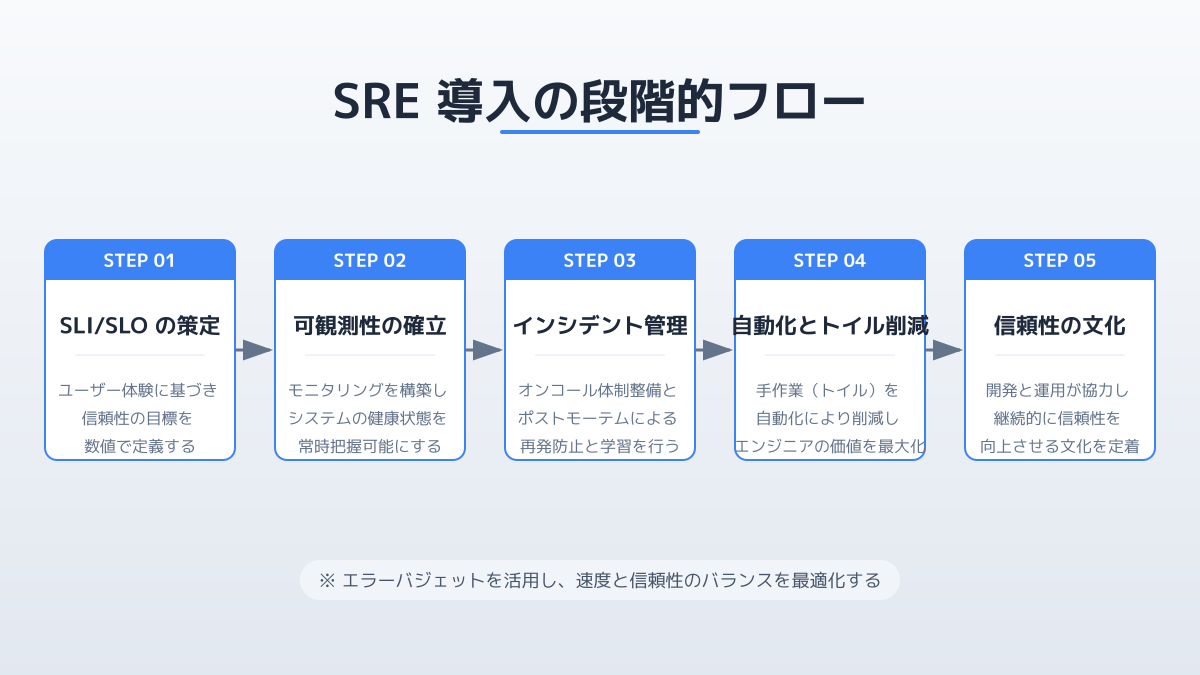
SREの手法を組織に導入する際は、いきなり全社レベルで適用するのではなく、段階的なアプローチを取ることが成功の鍵です。
まずはビジネスへの影響度が大きい、あるいは運用負荷がボトルネックになっている特定のコアシステム(例:決済APIや認証基盤)を選定します。そのシステムに対してエラーバジェットの設定やSLO(サービスレベル目標)の定義を行い、小さなチームで成功体験を積みます。そこで得られたノウハウや自動化の仕組みを、徐々に他のシステムや部署へ展開していくことで、現場の混乱を防ぎながら定着させることができます。
開発と運用の対立を解消する組織文化

SREが失敗する典型的なケースは、既存のインフラチームの名前を「SREチーム」に変えただけで、実際の働き方や評価基準が変わっていない状態です。
SREの本来の価値を引き出すには、開発チームと運用チームの対立構造を解消しなければなりません。「開発は新機能を出したい」「運用はシステムを止めたくない」という相反する利害を、エラーバジェットという共通のルールで管理します。両者が「サービスの価値をユーザーに安全かつ迅速に届ける」という同じ目標に向かって協力する文化を根付かせることが不可欠です。
非難なき事後検証(ポストモーテム)
システムを運用していれば、どれほど強固な対策をしても障害は発生します。SREにおいて重要なのは、インシデントが発生した後の対応です。
具体的な運用トラブルの解決例として、デプロイミスによりデータベースの接続障害が起きた場合を想定します。障害の振り返り(ポストモーテム)を行う際、「誰がスクリプトを間違えたのか」といった個人の責任を追及してはいけません。非難される環境では、担当者がミスを隠そうとし、根本的な原因解決から遠ざかるためです。
SREでは常に「なぜ間違ったコマンドを実行できる権限設計になっていたのか」「テスト環境で検知できなかった理由は何か」を客観的に分析する「非難なき事後検証」を徹底します。実際のポストモーテムのサンプルフォーマットと記入例は以下の通りです。
- 発生事象のタイムライン:14:00 新バージョンデプロイ、14:03 エラー検知アラート発報、14:15 ロールバック完了により復旧
- 影響範囲:約15分間、全ユーザーのログインおよび決済処理が失敗。該当件数約120件。
- 根本原因(Root Cause):データベースのマイグレーションスクリプトに構文エラーが存在。テスト環境と本番環境のDBバージョン差異により、事前テストをすり抜けてしまった。
- 再発防止アクション(Action Items):テスト環境のDBバージョンを本番と自動同期する仕組みの構築(担当:インフラチーム、期限:次週)、CI/CDパイプラインに厳格な構文チェック処理を追加(担当:開発チーム、期限:今週中)
このプロセスを通じて、CI/CDパイプラインへの自動テストの追加や権限設定の見直しを行い、二度と同じ障害が起きない仕組みを構築します。属人的なミスを責めるのではなく、システム側の防御壁を厚くすることが、インフラ運用を成功に導く基本です。
まとめ
SRE(Site Reliability Engineering)は、手作業でのインフラ運用から脱却し、ソフトウェアの力でシステムの信頼性と開発速度を両立させる実践的なアプローチです。本記事で解説した8つの原則を振り返ります。
- インフラ運用をソフトウェアエンジニアリングで解決する
- DevOpsの理想を具体的な手法として実践する
- エラーバジェットで稼働率と開発速度のバランスを取る
- 運用を圧迫するトイル(手作業)を自動化して削減する
- SREエンジニアがインフラと開発の橋渡しを担う
- スモールスタートで段階的に導入する
- 開発と運用の対立を解消する組織文化を醸成する
- 非難なき事後検証で継続的なシステム改善を行う
SREとは何かを正しく理解し、具体的な事例を参考に自社の運用へ少しずつ取り入れることで、ビジネスの成長を加速させるスケーラブルなインフラ基盤を実現してください。
この記事を書いた人

タジケン
テクラル合同会社
一部上場企業を経て広告代理店に入社し、デジタルマーケティングの知見を深める。現在はテクラルにて、数千万規模の大型案件でプロジェクトリードを担当。KPI設計や広告運用などのマーケティング領域から、AIを活用したシステム開発の導入支援までプロダクトの成長を一気通貫でサポートしている。本ブログでは、事業フェーズに合わせた実践的なノウハウをお届けする。