データ基盤構築で失敗しない7つの手順!アーキテクチャ設計と運用ポイント
タジケン
テクラル合同会社

データ基盤構築でプロジェクトが失敗する最大の理由は、現場の目的が曖昧なままツール導入を先行させてしまうことです。まずは特定部門の課題解決に絞ってスモールスタートし、段階的に全社展開していくアプローチが成功の鍵となります。本記事では、導入目的の明確化から最適なデータ基盤アーキテクチャの設計、運用体制の構築まで、失敗しないための7つの重要ポイントを具体的な事例や数値を交えて解説します。
ポイント1:導入目的の明確化とスモールスタート
データ活用を推進するにあたり、最初のステップとして押さえておくべき最重要事項は「導入目的の明確化」です。単にデータを一箇所に集めるだけでは、ビジネスの成果には直結しません。
何のためにデータ基盤を構築するのか、その目的を現場レベルで具体化することが不可欠です。「経営陣がKPIをリアルタイムで把握するため」か、「マーケティング部門が顧客行動を分析するため」かによって、求められるアーキテクチャや処理速度は根本から変わります。
また、最初から全社展開を目指すのはリスクが高いため、特定部門から小さく始めるスモールスタートが推奨されます。ある中堅小売企業では、マーケティング部門の顧客分析に絞ってデータ基盤を構築し、導入後3ヶ月でキャンペーンのCVR(コンバージョン率)を1.5倍に改善しました。この小さな成功体験と明確なROI(投資対効果)を社内に提示することで、その後の全社展開をスムーズに進めることができました。
ポイント2:目的に応じたアーキテクチャ設計
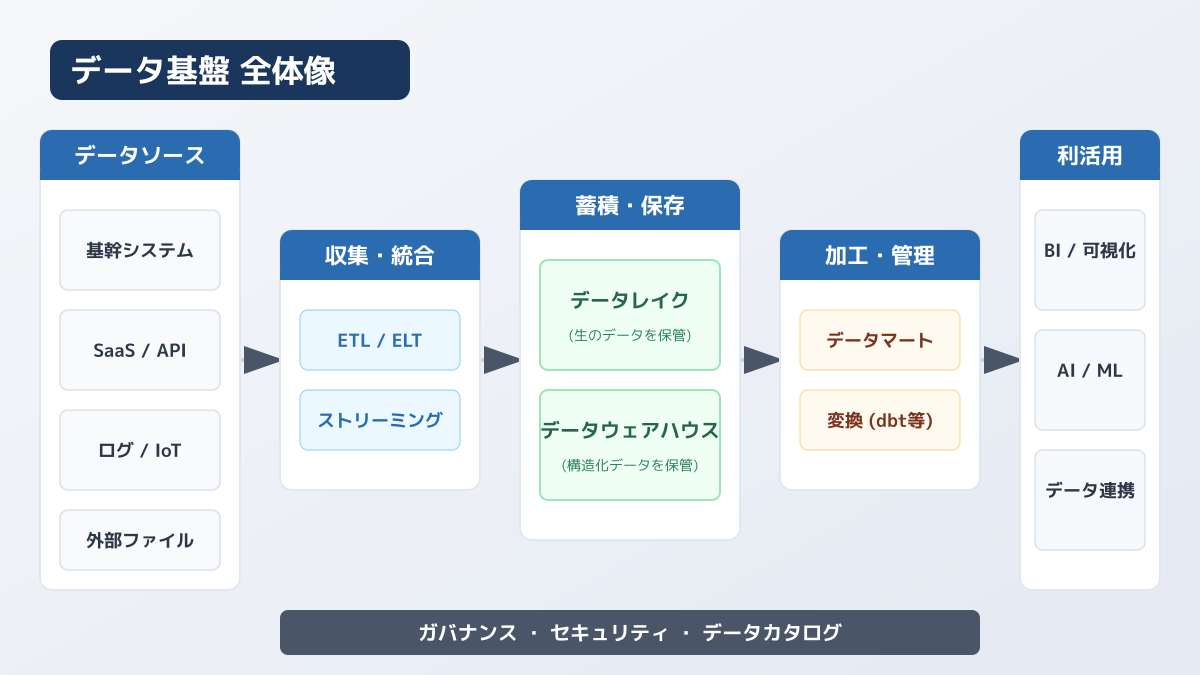
データ活用を成功に導くためには、目的に応じたデータ基盤アーキテクチャの設計が不可欠です。
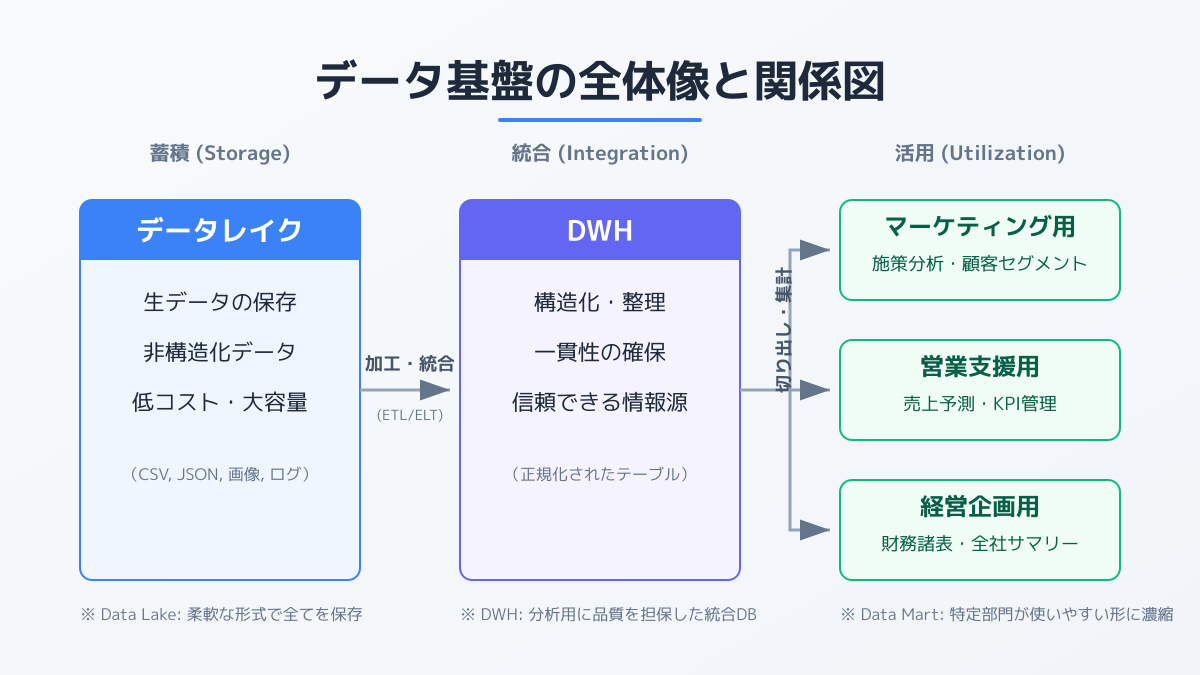
データ基盤を構成する主要な要素として、あらゆるデータをそのまま保存する「データレイク」と、分析用に構造化して格納する「DWH(データウェアハウス)」があります。アーキテクチャ設計では、これらの要素を各クラウドベンダーのマネージドサービスで組み合わせるのが現在の主流です。
具体的な構成図のイメージとして、AWSとGCPを活用した定番の組み合わせ例を挙げます。
- AWS構成例:データレイクにAmazon S3を採用し、データの変換・加工(ETL処理)をAWS Glueで実行。分析用DWHとしてAmazon Redshiftに格納し、Amazon QuickSightで可視化する構成です。既存システムがAWS環境に多く、多様なマネージドサービスを柔軟に連携させたいケースに適しています。
- GCP構成例:データレイクにCloud Storage、データ処理にフルマネージドなDataflowを採用し、強力な分析基盤であるBigQueryへ集約。Lookerでダッシュボード化する構成がよく使われます。特にペタバイト級のビッグデータ分析や、機械学習モデルの早期適用を重視するプロジェクトで強みを発揮します。
自社に最適なアーキテクチャを決定する際は、「データの鮮度」と「分析の複雑さ」が判断基準になります。日次の売上レポート作成であれば夜間バッチ処理で十分ですが、ユーザーの行動ログを即座にレコメンドエンジンに反映させたい場合は、ストリーミング処理を前提とした設計が必要です。
なお、自社プロダクトとしてSaaSを展開する場合、マルチテナント環境でのデータ分離やセキュリティ要件も複雑になります。SaaSのインフラ設計を含めた全体像については、SaaS開発とは?費用相場から技術選定、MVP構築の手順まで完全ガイドを参考にしてください。
ポイント3:効率的なデータパイプライン構築
各システムからデータを収集し、分析可能な状態に整えるデータパイプラインの設計は、プロジェクトの成否を分ける重要な要素です。

近年はクラウドDWHの計算能力向上により、データを先に抽出・ロードしてから基盤内で加工する ELT(Extract, Load, Transform)アプローチが主流です。たとえばdbt(data build tool)などのデータ変換ツールを用いてDWH内でSQLベースの加工を行うことで、開発効率と保守性が劇的に向上します。しかし、個人情報などの機密データを扱う場合は、ロード前にマスキング処理を行う ETL(Extract, Transform, Load)が適しています。
処理のリアルタイム性もビジネス要件に合わせて最適化する必要があります。ある製造業の事例では、生産ラインのセンサーデータを日次バッチからApache Kafka等を用いたストリーミング処理に変更し、異常検知のリードタイムを大幅に短縮しました。結果として、不良品の発生率を導入前の15%削減することに成功しています。
ポイント4:データ品質の維持とクレンジングの自動化
蓄積されるデータが不正確であれば、AIの予測精度やビジネスの意思決定に致命的な悪影響を及ぼします。そのため、データ品質の維持は運用フェーズにおける最重要課題です。
ゴミデータ(ノイズ)の混入を防ぐためには、データ入力時のルールを標準化し、パイプライン内で異常値や欠損値を検知・除外するクレンジング処理を自動化することが求められます。
手作業でのデータ整形に依存していると、工数が膨らむだけでなくヒューマンエラーの原因になります。あるIT企業では、各部署から集まるExcelデータのクレンジングを自動化したことで、月間40時間かかっていた集計作業を5時間に短縮(87.5%削減)し、本来の分析業務にリソースを集中できるようになりました。
ポイント5:データガバナンスとセキュリティの両立
データ基盤に蓄積される情報が常に信頼できる状態を保つためには、誰がどのデータにアクセスし、どのように管理するのかというデータガバナンスの確立が不可欠です。
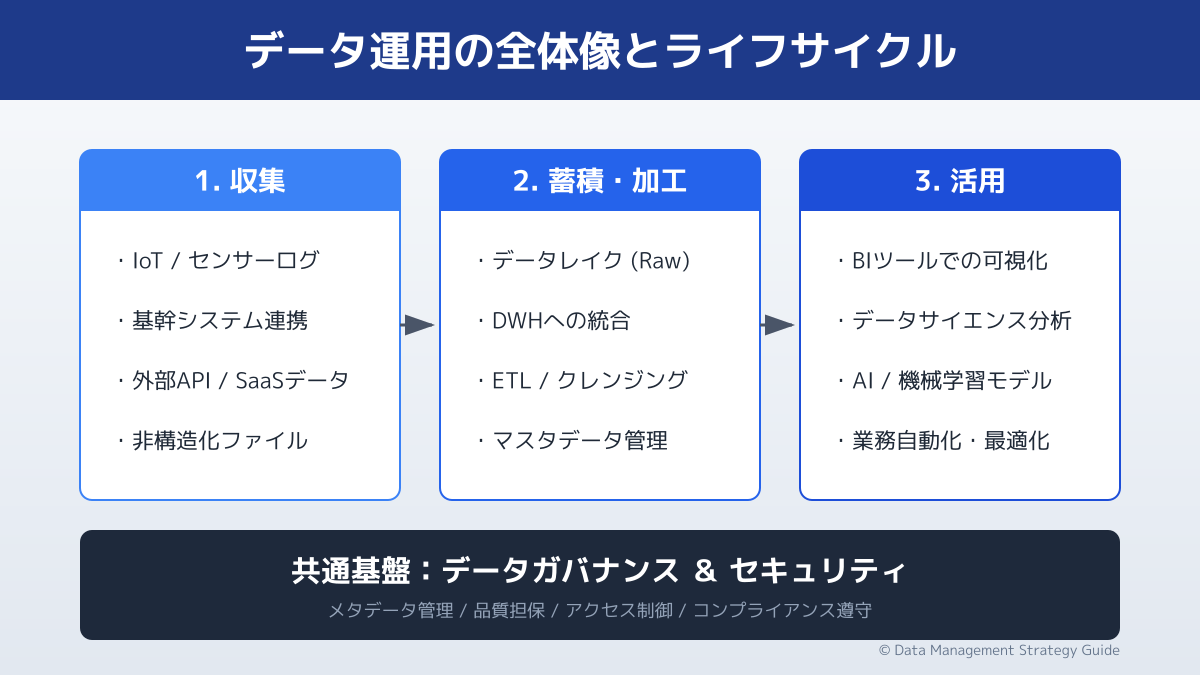
ガバナンス方針を決定する際は、「データの機密性」と「利用部門の範囲」を明確に切り分けます。個人情報や財務データなど厳格な管理が求められる領域と、全社的に広く活用したい領域を分類し、適切なアクセス権限を設定します。
現場運用における最大の注意点は、管理ルールを厳格にしすぎてデータの利活用が阻害されてしまうことです。必要なユーザーが迅速にデータへアクセスできる「データの民主化」と、機密性を守る「セキュリティ」のバランスを見極めることが、安全なデータ活用の第一歩となります。
ポイント6:継続的な運用監視と障害対応フロー
開発して終わりではなく、安全かつ効果的に活用し続けるための継続的な運用監視の仕組みづくりが求められます。
運用フェーズで多く発生するトラブルは、連携元システムの仕様変更に伴うデータパイプラインの停止や、連携エラーです。これらの問題を防ぐため、データ基盤への入力段階でデータ型やNull値のチェックを自動化するテスト機構を組み込みます。
異常を検知した際は、即座にデータエンジニアへアラートが通知される仕組みを構築します。ある金融機関では、自動監視ツールと障害対応フローを整備したことで、データ連携エラーの検知から復旧までのリードタイムを平均半日から1時間以内に短縮し、業務への影響を最小限に抑える体制を実現しました。
ポイント7:組織横断のデータ活用体制と人材育成
最後のポイントは、システムを使いこなすための組織横断的なデータ活用体制の構築です。一部のIT部門に管理業務が集中してしまうと、ビジネス部門のデータ活用が遅れ、意思決定のスピードが低下します。
各部門に「データスチュワード(データ管理者)」を配置し、現場主導でデータを安全に活用できる体制を作ることが不可欠です。あるSaaS企業では、各事業部にデータスチュワードを配置し、BIツールの使い方やデータ定義の社内研修を実施しました。その結果、データ抽出の依頼からレポート作成までの期間が平均1週間から即日に短縮され、データドリブンな意思決定が組織全体に定着しました。
また、近年は自然言語でデータを引き出せるAIツールの導入も進んでいます。【そのまま使える】生成AIプロンプトのテンプレートと書き方のコツなどを参考に、現場が迷わずデータにアクセスできる仕組みを整えることも、運用定着の鍵となります。
まとめ
企業のDX推進を加速させるデータ基盤構築において、成功を左右する7つの重要ポイントを解説しました。目的を明確にしたスモールスタートから始め、目的に応じたデータ基盤アーキテクチャと効率的なデータパイプラインを設計することが技術的な成功の鍵を握ります。
さらに、データ品質の維持、ガバナンスの確立、継続的な監視体制、そして組織横断的な活用体制の整備により、データは単なる記録からビジネスを牽引する強力な武器へと変わります。これらのポイントを網羅的に押さえ、自社の事業成長に直結するデータ基盤を実現してください。
この記事を書いた人

タジケン
テクラル合同会社
一部上場企業を経て広告代理店に入社し、デジタルマーケティングの知見を深める。現在はテクラルにて、数千万規模の大型案件でプロジェクトリードを担当。KPI設計や広告運用などのマーケティング領域から、AIを活用したシステム開発の導入支援までプロダクトの成長を一気通貫でサポートしている。本ブログでは、事業フェーズに合わせた実践的なノウハウをお届けする。