AWS障害情報をリアルタイムで確認する5つの方法|公式ダッシュボードと対処フロー【2026年版】
コセケン
テクラル合同会社

「AWSが今、障害で落ちているのか」を最短で確認するには、公式の AWS Health Dashboard(https://health.aws.amazon.com/health/status)を開くのが基本です。全サービス・全リージョンの稼働状況がリアルタイムで一覧表示され、影響を受けているサービスとリージョンがその場でわかります。第一報の速さでは X(旧Twitter)やDowndetectorのほうが早いこともあるため、公式と外部を組み合わせて確認するのが実務の鉄則です。
この記事を読むと、次の3点がわかります。
- AWS障害情報をリアルタイムで確認する5つの方法と、それぞれの使い分け
- 障害を検知してから復旧するまでの具体的な対処フロー
- 東京リージョンの過去事例から学ぶ、被害を最小化する設計のポイント
AWS障害情報をリアルタイムで確認する5つの方法
AWS障害をリアルタイムで把握するには、信頼性の高い公式情報と、速報性の高い外部情報を組み合わせます。代表的な5つの確認方法を、特徴とともに整理します。
| 確認方法 | 速報性 | 信頼性 | 主な用途 |
|---|---|---|---|
| AWS Health Dashboard(公式) | 中 | 高 | 全サービスの稼働状況を一次情報で確認 |
| Personal Health Dashboard(公式) | 高 | 高 | 自社アカウントに影響するイベントの通知 |
| RSSフィード | 高 | 高 | Slack・Teamsへの自動配信 |
| X(旧Twitter) | 高 | 中 | 第一報・他社の反応の把握 |
| Downdetector | 高 | 中 | ユーザー報告ベースの異常検知 |
それぞれの役割は次のとおりです。
- AWS Health Dashboard(公式): 全リージョン・全サービスの稼働状況を示す一次情報源。「自社の問題か、AWS側の障害か」を判断する起点になります。
- Personal Health Dashboard(公式): 自社が利用中のリソースに影響するイベントだけを通知してくれる、アカウント固有のダッシュボードです。
- RSSフィード: AWS Health Dashboardのサービス履歴画面から、特定サービス・リージョンのRSSを購読できます。SlackやMicrosoft Teamsに連携すれば、障害情報を自動でチームに流せます。
- X(旧Twitter): AWSの公式アカウント(@AWSCloud・@AWSJapan)やエンジニアの投稿で第一報をつかめます。公式発表より速いこともあります。
- Downdetector: ユーザーの障害報告を可視化するサービス。利用者の体感ベースなので、公式発表前に異常の兆候が見えることがあります。
公式ダッシュボードで事実を確定し、XやDowndetectorで速報をつかむ、という二段構えが最も漏れの少ない確認方法です。
AWS Health Dashboardの見方とCloudWatchによる能動的な検知
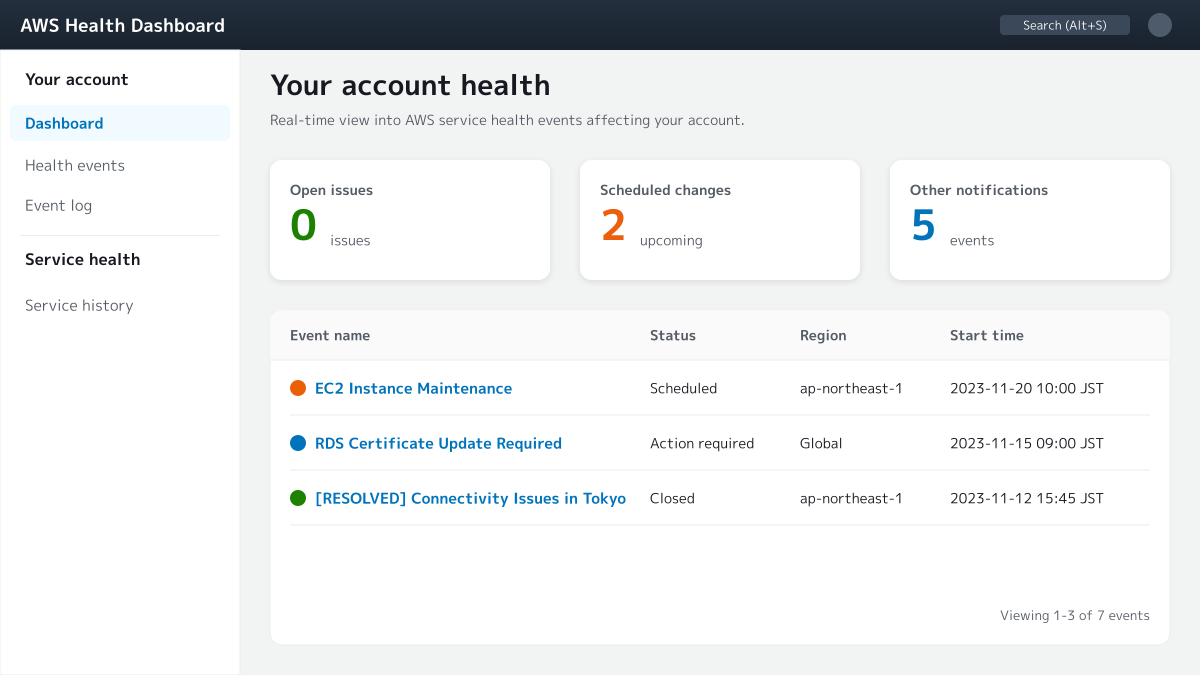
AWS Health Dashboard(https://health.aws.amazon.com/health/status)は、AWS全体の稼働状況を示す「Service Health」と、自社アカウント固有のイベントを通知する「Personal Health Dashboard」を一元化した公式ダッシュボードです。2021年にリニューアルされ、現在の形になりました。
画面上部の「Service health」をクリックすると、稼働中の全サービスの状態と、障害イベントの名称・発生リージョンが一覧で表示されます。ここで自社が使うサービス・リージョンに異常がなければ、原因は自社環境側にある可能性が高い、と切り分けられます。
ただし、ダッシュボードを人が見に行く運用では検知が遅れます。Amazon CloudWatch でカスタムアラームを設定しておけば、ダッシュボードを開く前に自動で異常を通知できます。EC2インスタンスのステータスチェック失敗やALBの5xxエラー率上昇などをトリガーに、Amazon SNS経由でSlackや担当者のメールへ通知する体制を整えておくと、初動が大幅に速くなります。公式ダッシュボードの「受け身の確認」と、CloudWatchの「能動的な検知」を併用するのが理想です。
障害発生時の対処フロー|検知から復旧までの5ステップ
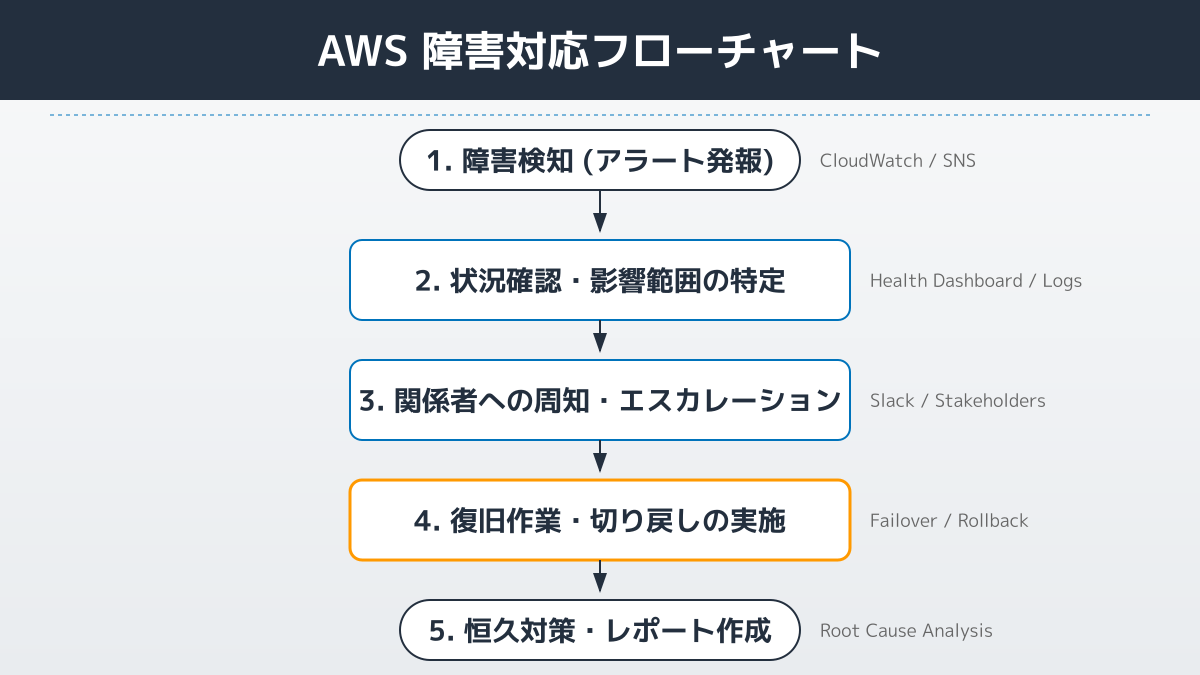
障害を確認できたら、慌てずに決められた手順で対処します。検知から復旧までは、次の5ステップで進めるのが基本です。
- 障害検知(アラート発報): CloudWatchアラームやSNS通知で異常を受け取る。第一報の段階です。
- 状況確認・影響範囲の特定: AWS Health Dashboardで「AWS側の障害か、自社環境の問題か」を切り分け、影響を受けるサービス・リージョンを確定します。
- 関係者への周知・エスカレーション: 事前に整備したエスカレーションフローに沿って、責任者・関係部署へ状況を共有します。
- 復旧作業・切り戻しの実施: マルチAZ・マルチリージョン構成ならフェイルオーバー、デプロイ起因なら切り戻し(ロールバック)を実施します。
- 恒久対策・レポート作成: 復旧後に原因分析(ポストモーテム)を行い、再発防止策をランブックに反映します。
この一連の流れを文書化したエスカレーションフローとランブック(対応手順書)を事前に用意しておくことが、復旧時間を左右します。自動復旧の仕組みを導入していても、想定外の事態に備えた手動対応のフローが明確でなければ、復旧までに多大な時間を要してしまいます。
過去の東京リージョンにおけるAWS障害事例と原因

過去の障害事例を知っておくと、どこに単一障害点が生まれやすいかを把握でき、設計の判断材料になります。東京リージョン(ap-northeast-1)で起きた代表的な2つの大規模障害を、原因とあわせて振り返ります。
| 発生日 | 直接の原因 | 主な影響 |
|---|---|---|
| 2019年8月23日 | データセンター制御システムのバグで空調設備が応答停止し、一部AZのEC2サーバーが過熱 | EC2・EBS・RDSのパフォーマンス劣化、多数のWebサービスが数時間ダウン |
| 2021年9月2日 | ネットワークデバイスのOSに追加された新プロトコル処理の潜在的なバグ | 一部EC2が停止、金融機関・航空会社など幅広いサービスに波及 |
2019年8月23日の障害は、単一のアベイラビリティーゾーン内で冗長化された空調設備の管理システムが、サードパーティ製コードのロジックのバグで応答しなくなり、EC2サーバーが過熱したことが原因でした。フェイルセーフや手動操作での復旧にも手間取り、大部分のインスタンスが回復したのは同日18時半ごろです(出典: AWS公式報告)。
2021年9月2日の障害は、Direct Connectロケーションから東京リージョンのデータセンターネットワークへ至る経路上で、ネットワークデバイスの一部に障害が発生したことが発端でした。原因は、2021年1月に本番投入されたネットワークデバイスのOSの新プロトコル処理に潜む欠陥で、特定のパケット属性が揃うと問題を引き起こすものでした。三菱UFJ銀行やみずほ銀行のアプリ、ネット証券、航空会社のシステムなどに影響が及んでいます(出典: ITmedia)。
これらの事例に共通する教訓は、単一のアベイラビリティーゾーンや特定のネットワーク経路への依存を避けることの重要性です。物理設備にもネットワーク経路にも単一障害点を作らない設計が、被害の最小化につながります。
障害に強いシステム設計のポイント
障害検知後の対応だけでなく、設計段階で被害を抑える仕組みも不可欠です。AWS Well-Architectedフレームワークの「信頼性の柱」では、システムが意図した機能を正確かつ一貫して実行する能力を高める原則が定義されており、障害からの自動復旧や設定ミスの軽減といった観点が含まれます。
実装面では、複数のAZやリージョンにまたがる冗長構成が基本になります。複数AZにリソースを分散すれば、特定の設備で物理障害が起きてもサービスを継続できます。サーバーレス構成を採用すると、インフラの冗長化を自動的に担保しながらコストを抑えられるため、新規事業の立ち上げフェーズとも相性が良い選択肢です。詳しくはAWSサーバーレスでWebアプリ開発で構成パターンを確認できます。一方で、サーバーレスにはコールドスタートやベンダーロックインといった注意点もあるため、サーバーレスのデメリットと向き不向きの判断基準もあわせて把握しておくと、設計の判断を誤りにくくなります。
冗長構成は「組んだら終わり」ではありません。マルチAZ・マルチリージョン構成を採用していても、フェイルオーバーのテストを行っていなければ、実際の障害時に想定通りトラフィックが切り替わらないリスクが残ります。定期的な復旧訓練(フェイルオーバーテスト)を運用に組み込み、いざというときに確実に切り替わる状態を保ちましょう。さらにAWSでのCI/CDパイプライン構築で復旧時のデプロイを自動化しておけば、手動作業のミスを減らし、復旧速度を高められます。
よくある質問(FAQ)
Q. AWSが今、障害で落ちているか今すぐ確認するには? A. まず公式のAWS Health Dashboard(health.aws.amazon.com/health/status)で全サービスの稼働状況を確認します。あわせてX(旧Twitter)の@AWSCloud・@AWSJapanやDowndetectorを見ると、第一報や他社の状況をより速くつかめます。
Q. AWS障害情報の公式な一次情報源はどこですか? A. AWS Health Dashboardが公式の一次情報源です。旧URLのstatus.aws.amazon.comは現在health.aws.amazon.comにリダイレクトされます。自社アカウントに影響するイベントは、サインイン後のPersonal Health Dashboardで確認できます。
Q. 障害をリアルタイムで自動通知させる方法は? A. AWS Health DashboardのRSSフィードをSlackやMicrosoft Teamsに連携する方法と、CloudWatchアラームをAmazon SNS経由で通知する方法があります。前者はAWS側のイベント通知、後者は自社リソースの異常検知に向いています。
Q. 自社環境の問題かAWS障害かを切り分けるには? A. AWS Health Dashboardで該当サービス・リージョンに障害イベントが出ているかを確認します。公式に異常がなければ、設定やアプリケーション側の問題である可能性が高いと判断できます。
Q. 障害に補償(返金)はありますか? A. EC2やRDSなど多くのサービスにはSLAが定められており、稼働率が基準を下回った場合にサービスクレジットが付与される仕組みがあります。条件や申請方法はサービスごとに異なるため、各サービスのSLA条項を確認してください。
まとめ
AWS障害は完全には避けられないリスクですが、リアルタイムの確認手段と対処フローを整えておけば、影響を最小限に抑えられます。本記事の要点は次のとおりです。
- AWS障害情報のリアルタイム確認は、公式のAWS Health Dashboardを起点に、X・Downdetectorなど外部ソースを併用する
- CloudWatchアラームとSNS通知で、ダッシュボードを見る前に異常を自動検知する体制を整える
- 障害対応は「検知→状況確認→周知→復旧→恒久対策」の5ステップで進め、ランブックとエスカレーションフローを事前に用意する
- 東京リージョンの過去事例が示すとおり、単一のAZ・ネットワーク経路への依存を避け、冗長構成とフェイルオーバーテストで備える
これらの対策を講じることで、予期せぬトラブルにも迅速に対応し、安定したプロダクト運用の基盤を築くことができます。
この記事を書いた人

コセケン
テクラル合同会社
スタートアップでのCTO経験を経て、現在はテクラル合同会社にてシステム開発全般を牽引しています。アプリおよびWebの開発から、バックエンド、インフラ構築に至るまで幅広い技術領域に対応可能です。スピード感を持った品質の高いシステム開発を得意としており、新規プロダクトの立ち上げを一気通貫で支援します。本ブログでは実践的な開発ノウハウを発信していきます。