アプリのオフライン対応と同期設計|ローカルDB・競合解決の実装と外注判断【2026年版】
コセケン
テクラル合同会社
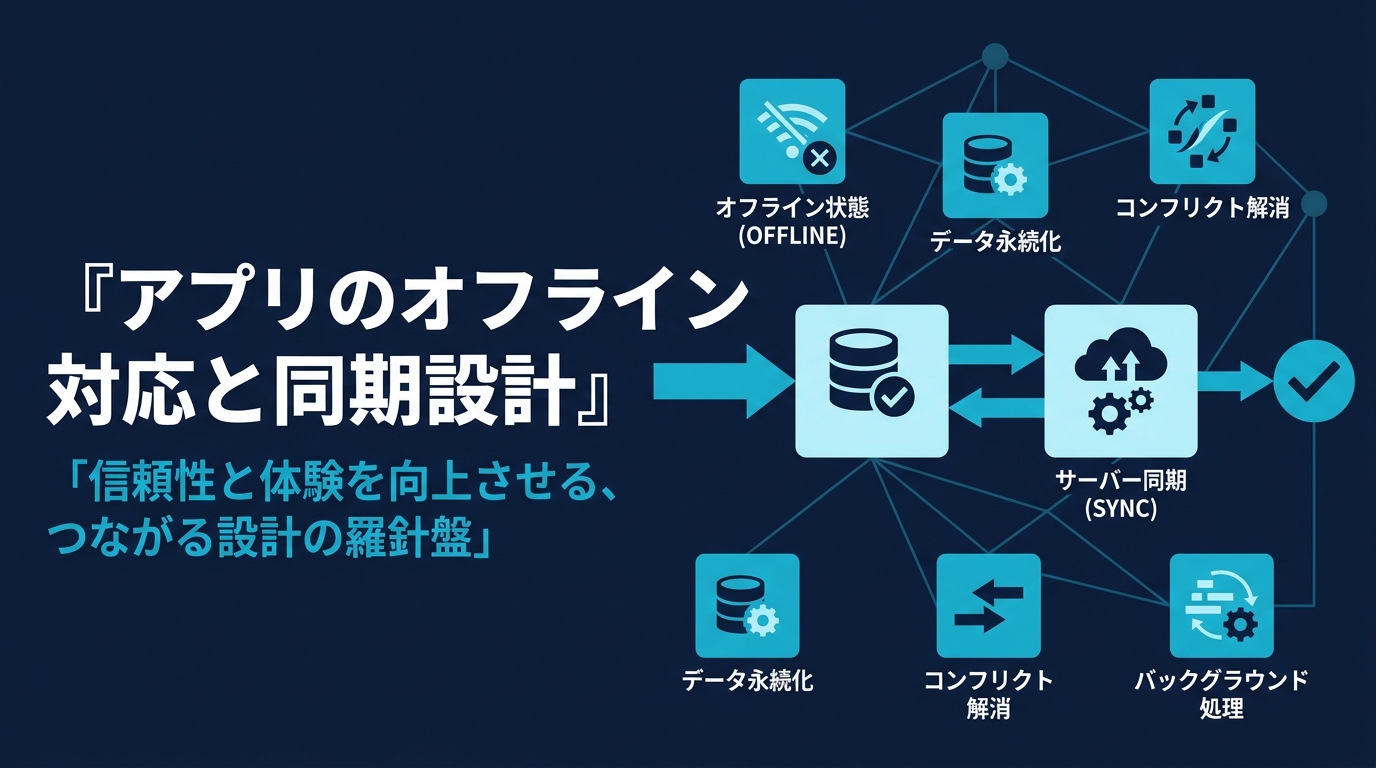
アプリのオフライン対応で最も破綻しやすいのは「データの保存」ではなく「同期と競合解決」です。圏外でもアプリが動くこと自体は、端末内に SQLite などのローカルDBを持てば実現できます。難所は、複数の端末がオフラインで同じデータを書き換え、後からサーバーへ反映したときに「どの変更を正とするか」を一貫したルールで決める部分にあります。本記事では、オフラインファースト設計の全体像、ローカルDBの選び方、競合解決の3つの戦略(last-write-wins / サーバー権威モデル / CRDT)を実装レベルで整理し、最後に「どこまで内製し、どこから外注すべきか」の判断軸を示します。
オフライン対応の本質は「同期」であり「保存」ではありません
結論として、オフライン対応の設計コストの大半は同期レイヤーに集中します。理由は、ローカル保存が単一端末で完結する問題なのに対し、同期は「ネットワークの断続」「複数端末の並行更新」「部分的な失敗」という分散システム特有の難問を同時に抱えるからです。
具体的には、オフライン対応アプリは少なくとも次の4つの責務を持ちます。
- ローカル保存:圏外でも読み書きできる端末内データストア(SQLite など)
- 変更キュー:オフライン中の書き込みを順序付きで貯めておく仕組み
- 同期エンジン:再接続時にサーバーと差分をやり取りする処理
- 競合解決:同じデータが別々に更新されたときの調停ルール
このうち「ローカル保存」は既存ライブラリで容易に解決できます。一方で残り3つ、特に競合解決は、仕様の曖昧さがそのままデータ破損や「保存したはずの内容が消えた」という障害につながります。設計の初期段階でここを詰めずに走り出すと、リリース後に作り直しになるのが典型的な失敗です。
オフラインファースト設計の基本構造
オフラインファーストとは、「ローカルDBを正(Source of Truth)として UI を駆動し、サーバー同期はバックグラウンドで行う」アーキテクチャです。ネットワークを前提にした従来型(サーバーに毎回問い合わせ、結果を表示する)と逆向きで、UI は常にローカルDBだけを見ます。
この構造を採ると、画面は通信状態に依存しなくなり、体感速度も向上します。実装の骨格は次のようになります。
[UI / 画面]
│ 読み取りは常にローカルDBから(リアクティブに購読)
▼
[ローカルDB(SQLite など)] ←─ Source of Truth
│ 書き込みは即ローカルへ → 変更キューに積む
▼
[変更キュー(outbox / upload queue)]
│ オンライン復帰時に順次フラッシュ
▼
[同期エンジン] ──HTTP/WebSocket──► [サーバー / バックエンドDB]
│
サーバー側で競合判定・確定
ポイントは、UI が「書き込み完了」を待つのはローカルDBへの保存までで、サーバー反映は待たないことです。これにより圏外でも操作が完結します。同期エンジンは復帰時に変更キューを古い順(FIFO)にサーバーへ送り、サーバーが受理・拒否を返す、という流れになります。
ローカルDBの選び方(2026年時点)
ローカルDBは、ほぼ全てのケースで SQLite を基盤に選ぶのが堅実です。理由は、モバイル OS にネイティブ同梱され、トランザクション・インデックス・WAL(Write-Ahead Logging)モードによる読み書きの並行性まで揃っているためです。問題は「SQLite を直接叩くか、上位ライブラリを使うか」の選択になります。
主要な選択肢を、開発フレームワーク別に整理します。
| 選択肢 | 対応フレームワーク | 同期機能 | 特徴 |
|---|---|---|---|
| expo-sqlite / 生 SQLite | React Native (Expo) | なし(自前実装) | OS 標準の SQLite に薄くアクセス。同期は自分で書く |
| Drizzle / Drift などの ORM | React Native / Flutter | なし(自前実装) | 型安全なクエリとマイグレーション。リアクティブ購読に対応 |
| WatermelonDB | React Native 中心 | 同期プロトコルの仕様あり(サーバーは自前) | SQLite 上の高速・リアクティブDB。大規模データ向け。同期は規約に沿って自前構築 |
| PowerSync | Flutter / React Native / Kotlin / Swift | 同期エンジンを提供 | Postgres / MongoDB の変更を SQLite にストリーミング。設定主体で同期を解決 |
選定の軸はシンプルです。同期を「自分で作る」か「製品に任せる」かで大きく分かれます。WatermelonDB や生 SQLite + ORM は制御性が高い反面、同期エンジンと競合解決を自前で実装する工数が乗ります。PowerSync のような同期プラットフォームは実装量を大きく削れますが、外部サービスへの依存と継続的なコストが発生します。
なお、どの選択肢でも SQLite を使う場合は、起動時に一度だけ WAL モードと busy_timeout を設定しておくと、UI 読み取りとバックグラウンド書き込みの競合によるロック失敗を避けられます。
PRAGMA journal_mode = WAL;
PRAGMA busy_timeout = 5000; -- ロック時に即失敗させず最大5秒待つ
PRAGMA foreign_keys = ON;
公式ドキュメント(Expo SQLite)でも、WAL の有効化はパフォーマンス改善の推奨設定として案内されています。
競合解決の3戦略:ここが設計の山場です
競合解決は「last-write-wins」「サーバー権威モデル」「CRDT」の3択で、扱うデータの性質によって最適解が変わります。結論を先に言うと、単純なフィールド更新なら last-write-wins、業務ロジックを伴う更新ならサーバー権威モデル、共同編集ならCRDT が基本線です。1つの方式で全てを賄おうとすると破綻します。
1. Last-Write-Wins(最終書き込み優先)
タイムスタンプが新しい更新で古い更新を上書きするだけの、最もシンプルな方式です。実装は容易ですが、「同時に別フィールドを編集した変更を丸ごと捨てる」リスクがあります。プロフィール設定のような、競合頻度が低く粒度の細かいデータには有効です。
// レコード単位の last-write-wins(updated_at で比較)
function resolveLWW<T extends { id: string; updated_at: number }>(
local: T,
remote: T,
): T {
return remote.updated_at >= local.updated_at ? remote : local;
}
ただし端末ごとに時計がずれるため、サーバー受信時刻や論理クロック(後述の Lamport timestamp)で比較するのが安全です。端末のローカル時刻をそのまま信用すると、時計が進んだ端末の更新が常に勝つという不公平が起きます。
2. サーバー権威モデル(server-authoritative)
サーバーを唯一の判定者とし、クライアントは「変更の意図(操作)」だけを送り、確定はサーバーが行う方式です。在庫・残高・予約枠のように「整合性が金銭やビジネスに直結する」データに必須です。
代表的な同期プラットフォームである PowerSync も、この考え方を前提に設計されています。公式ドキュメント(PowerSync Consistency)によれば、クライアントの書き込みは upload queue にブロッキング FIFO で積まれ、バックエンドが受理を確認するまで次のチェックポイントへ進まないため、クライアントはローカルで競合を解決しません。競合の最終判定はサーバー側(開発者が実装するバックエンド)に委ねられ、最も単純な実装では「last-write-wins(最後の書き込みが勝つ・削除は常に勝つ)」になりますが、業務ルールに沿って受理・拒否・再試行を自由に設計できます。整合性が金銭やビジネスに直結するデータでは、この受理/拒否のロジックを自前で書くことになります。
// サーバー権威:クライアントは「絶対値」でなく「操作」を送る
// 例: 在庫を2減らす(最終在庫数を送らない)
type Mutation =
| { op: "decrement_stock"; productId: string; by: number }
| { op: "set_profile_name"; userId: string; value: string };
// サーバー側で現在値を読み、業務ルールで受理/拒否を判定する
async function applyMutation(m: Mutation) {
if (m.op === "decrement_stock") {
const current = await db.getStock(m.productId);
if (current < m.by) {
return { status: "rejected", reason: "out_of_stock" }; // 拒否を返す
}
await db.setStock(m.productId, current - m.by);
return { status: "accepted" };
}
// ...
}
肝は、クライアントが「在庫を3にする」という最終値ではなく「在庫を2減らす」という操作(intent)を送る点です。最終値を送ると、2端末が同時に在庫を減らしたとき片方の減算が消えますが、操作を送ればサーバーで順に適用でき、整合性を保てます。
3. CRDT(Conflict-free Replicated Data Type)
CRDT は、複数端末の並行更新を数学的に「必ず同じ結果へ収束する」よう設計されたデータ構造で、共同編集・メモ・ホワイトボードのように「全員の変更を残したい」用途に向きます。代表ライブラリは Yjs と Automerge です。
Automerge 公式は、Lamport timestamp と actor ID による決定的なアルゴリズムで全レプリカを同一状態へ収束させると説明しています。Yjs はテキスト編集に最適化されたシーケンス CRDT を実装し、エディタ連携が豊富です。
ただし CRDT は万能ではありません。マージ用のメタデータでデータ量が膨らみやすく、「在庫はマイナスにできない」といった業務制約(不変条件)は CRDT 単体では表現できません。共同編集のテキストやリストには強力ですが、整合性ルールが必要な業務データに無理に適用すると、かえって複雑化します。
3戦略の使い分けをまとめます。
| 戦略 | 向くデータ | 競合時の挙動 | 主な実装コスト |
|---|---|---|---|
| Last-write-wins | 設定・プロフィール等の低競合データ | 新しい方で上書き(負けた変更は消える) | 低 |
| サーバー権威モデル | 在庫・残高・予約等の整合性必須データ | サーバーが受理/拒否を判定 | 中(バックエンド設計が要) |
| CRDT | 共同編集・メモ・図形等 | 全変更を収束マージ | 高(データ膨張・制約表現に注意) |
ありがちな破綻パターンと回避策
オフライン同期で起きる障害の多くは、設計時に詰め切れなかった「境界ケース」から発生します。代表的なものを挙げます。
- 端末時刻を信用した競合判定:時計のずれた端末の更新が常に勝つ/消える。サーバー時刻か論理クロックで比較します。
- 冪等性のない再送:通信断で応答を受け取れず再送した結果、同じ操作が二重適用される(例:二重課金)。各操作に一意のクライアント生成 ID を付け、サーバーで重複を弾きます。
- 変更キューの順序崩れ:作成前に更新が届くなどの順序逆転。キューは FIFO を厳守し、依存関係を保ったまま送ります。
- マイグレーションの非対称:ローカルDBのスキーマとサーバーのスキーマがバージョンずれを起こし、古い端末が新形式を解釈できない。スキーマ変更は前方・後方互換を意識して設計します。
- 「オフラインです」のまま放置:再接続時の自動再同期がなく、ユーザーが手動更新するまでデータが古いまま。なお Apple のApp Review Guidelines(4.2 Minimum Functionality)では、ブラウザ標準のオフラインエラーをそのまま見せるような最小機能のアプリは審査で問題視されます。オフライン時もネイティブらしい体験を維持する設計が求められます。
これらはいずれも「実装の難しさ」ではなく「仕様を決めていなかった」ことが原因です。設計フェーズでデータごとに競合戦略と境界ケースの挙動を表にしておくだけで、相当数を未然に防げます。
内製と外注の判断軸:設計フェーズで委託する価値
オフライン同期は「設計の正しさが後から取り返しにくい」領域のため、内製で進める場合でも設計フェーズだけは外部の知見を入れる価値が高い分野です。判断軸を整理します。
| 観点 | 内製で進めやすい | 外注・設計委託を検討すべき |
|---|---|---|
| 競合の性質 | 低競合・last-write-wins で足りる | 在庫/残高など整合性必須、または共同編集 |
| チームの経験 | 分散システム・同期実装の経験者がいる | 同期実装が初めて/知見が属人化している |
| データの重要度 | 消えても再取得できるキャッシュ的データ | 消失が事故になる業務・金銭データ |
| スケジュール | 試行錯誤の時間を確保できる | リリース後の作り直しが許容されない |
特に、競合解決の戦略選定とスキーマ・変更キューの設計は、後から変えるとデータ移行を伴う大手術になります。ここを「動くもの」だけで判断して走り出すと、ユーザーデータが増えた後の修正コストが跳ね上がります。
実務的な落としどころとしては、ローカルDBの導入や画面側の実装は内製しつつ、競合戦略の選定・同期プロトコルの設計・境界ケースの洗い出しを設計レビューとして切り出す分担が現実的です。オフライン同期を含むモバイルアプリの設計・実装の経験があるチームであれば、データの性質から「どの方式をどこに適用すべきか」をフェーズ初期に固められます。自社のデータがどの競合戦略に当たるのかを切り分ける段階こそ、最も投資対効果の高いタイミングだと言えます。
オフライン対応は「圏外でも動く」という表面的な要件の裏に、分散システムとしての設計判断が隠れています。ローカルDBの選定よりも、競合解決の戦略をデータごとに正しく割り当てられるかが、本番運用に耐えるかどうかを分けます。まずは自社アプリの主要データを「設定系・整合性必須系・共同編集系」に仕分け、それぞれにどの戦略を当てるかを設計の最初に決めることが、作り直しを避ける最短ルートです。
この記事を書いた人

コセケン
テクラル合同会社
スタートアップでのCTO経験を経て、現在はテクラル合同会社にてシステム開発全般を牽引しています。アプリおよびWebの開発から、バックエンド、インフラ構築に至るまで幅広い技術領域に対応可能です。スピード感を持った品質の高いシステム開発を得意としており、新規プロダクトの立ち上げを一気通貫で支援します。本ブログでは実践的な開発ノウハウを発信していきます。


